add code examples
This commit is contained in:
parent
d31191714d
commit
c39b22cc46
21 changed files with 206 additions and 12 deletions
assets/scss
content
code
work
layouts
resources/_gen/assets/scss/scss
static/images
|
|
@ -1,6 +1,6 @@
|
||||||
.button {
|
.button {
|
||||||
background: #0060ff;
|
background: #0060ff;
|
||||||
color: white;
|
color: white !important;
|
||||||
width: max-content;
|
width: max-content;
|
||||||
font-size: clamp(1em,2vw,1em);
|
font-size: clamp(1em,2vw,1em);
|
||||||
padding: 0.75em;
|
padding: 0.75em;
|
||||||
|
|
@ -9,4 +9,5 @@
|
||||||
text-decoration: none;
|
text-decoration: none;
|
||||||
border-radius: 100em;
|
border-radius: 100em;
|
||||||
font-weight: 700;
|
font-weight: 700;
|
||||||
|
|
||||||
}
|
}
|
||||||
32
assets/scss/base/links.scss
Normal file
32
assets/scss/base/links.scss
Normal file
|
|
@ -0,0 +1,32 @@
|
||||||
|
a:link,
|
||||||
|
a:visited {
|
||||||
|
color: inherit;
|
||||||
|
text-decoration-color: #0060ff;
|
||||||
|
transition:
|
||||||
|
text-decoration-thickness 200ms ease-out,
|
||||||
|
text-underline-offset 200ms ease-out,
|
||||||
|
text-decoration-color 200ms ease-out,
|
||||||
|
color 200ms ease-out
|
||||||
|
;
|
||||||
|
}
|
||||||
|
|
||||||
|
a:hover, a:focus, a:active {
|
||||||
|
text-decoration-color: #0060ff;
|
||||||
|
}
|
||||||
|
|
||||||
|
a:link {text-underline-offset: -0.075em;}
|
||||||
|
a:hover {text-underline-offset: -0.375em;}
|
||||||
|
|
||||||
|
@supports (text-decoration-thickness: 1em) {
|
||||||
|
a:link {
|
||||||
|
text-decoration-thickness: 0.125em;
|
||||||
|
text-underline-offset: 0.125em;
|
||||||
|
text-decoration-skip-ink: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
a:hover {
|
||||||
|
color: white;
|
||||||
|
text-decoration-thickness: 1.125em;
|
||||||
|
text-underline-offset: -0.875em;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
@ -27,7 +27,7 @@
|
||||||
.page-summary {margin: 1em 0;}
|
.page-summary {margin: 1em 0;}
|
||||||
.page-cover {width: 100%;}
|
.page-cover {width: 100%;}
|
||||||
|
|
||||||
h1,h2,h3,h4,h5,h6 {line-height: 1.2; margin-bottom: 1rem;}
|
h1,h2,h3,h4,h5,h6 {line-height: 1.2; margin-bottom: 1rem; margin-top: 2rem;}
|
||||||
p {
|
p {
|
||||||
line-height: 1.4;
|
line-height: 1.4;
|
||||||
margin-bottom: 1em;
|
margin-bottom: 1em;
|
||||||
|
|
@ -40,10 +40,8 @@
|
||||||
h6 {font-size: 1em}
|
h6 {font-size: 1em}
|
||||||
|
|
||||||
blockquote {
|
blockquote {
|
||||||
font-size: 1.5em;
|
font-size: 1em;
|
||||||
@media (min-width: 600px) {font-size: 2em}
|
|
||||||
margin: 1em 0;
|
margin: 1em 0;
|
||||||
font-family: serif;
|
|
||||||
border-left: 0.25rem solid black;
|
border-left: 0.25rem solid black;
|
||||||
padding-left: 0.5em;
|
padding-left: 0.5em;
|
||||||
}
|
}
|
||||||
|
|
@ -105,6 +103,9 @@
|
||||||
li {margin-bottom: 0; margin-left: 0;}
|
li {margin-bottom: 0; margin-left: 0;}
|
||||||
li li {margin-left: 1em;}
|
li li {margin-left: 1em;}
|
||||||
a {
|
a {
|
||||||
|
background: unset;
|
||||||
|
text-decoration-thickness: unset;
|
||||||
|
text-underline-offset: unset;
|
||||||
color: inherit;
|
color: inherit;
|
||||||
text-decoration: none;
|
text-decoration: none;
|
||||||
transition: color 0.2s ease-in-out;
|
transition: color 0.2s ease-in-out;
|
||||||
|
|
|
||||||
5
assets/scss/index/index.scss
Normal file
5
assets/scss/index/index.scss
Normal file
|
|
@ -0,0 +1,5 @@
|
||||||
|
#contact {
|
||||||
|
.section-heading {font-weight: 700;}
|
||||||
|
p {line-height: 1.4; max-width: 65ch; margin: 0 auto;}
|
||||||
|
.cta {margin: 6em auto 0;}
|
||||||
|
}
|
||||||
|
|
@ -1,9 +1,11 @@
|
||||||
@import "base/reset.scss";
|
@import "base/reset.scss";
|
||||||
|
@import "base/links.scss";
|
||||||
@import "base/sections.scss";
|
@import "base/sections.scss";
|
||||||
@import "base/page.scss";
|
@import "base/page.scss";
|
||||||
@import "base/list.scss";
|
@import "base/list.scss";
|
||||||
@import "base/components.scss";
|
@import "base/components.scss";
|
||||||
|
|
||||||
|
@import "index/index.scss";
|
||||||
@import "index/hero.scss";
|
@import "index/hero.scss";
|
||||||
@import "index/cards.scss";
|
@import "index/cards.scss";
|
||||||
@import "index/testimonials.scss";
|
@import "index/testimonials.scss";
|
||||||
|
|
|
||||||
|
|
@ -1,3 +1,3 @@
|
||||||
---
|
---
|
||||||
title: "Coding projects"
|
title: "Code written"
|
||||||
---
|
---
|
||||||
52
content/code/certbot-namecheap/index.md
Normal file
52
content/code/certbot-namecheap/index.md
Normal file
|
|
@ -0,0 +1,52 @@
|
||||||
|
---
|
||||||
|
title: "Certbot DNS-01 hook for Namecheap"
|
||||||
|
summary: "A manual auth hook for Certbot, implementing the DNS-01 challenge with Namecheap as the provider. Written in Python."
|
||||||
|
date: "2019-10-30"
|
||||||
|
tags: ["namecheap", "certbot", "dns-01", "python", "letsencrypt"]
|
||||||
|
cover: "/images/namecheap.jpg"
|
||||||
|
---
|
||||||
|
|
||||||
|
## The problem
|
||||||
|
|
||||||
|
I want to obtain Let's Encrypt certificates with wildcard subdomains, but to do so, one must prove that they own the entire domain and not just a particular subdomain. This means that the standard HTTP challenges are not enough.
|
||||||
|
|
||||||
|
I was tired of manually doing DNS-01 challenges through Namecheap's dashboard, which involved a laborious process of logging in, navigating to the domain I wanted to obtain certificates for, copying and pasting a special challenge code into a TXT record, waiting for the change to propagate, and repeating this for every single domain I owned, every three months.
|
||||||
|
|
||||||
|
## The research
|
||||||
|
|
||||||
|
Certbot plugins are available for some DNS providers, but Namecheap is not one of those. I was faced with two options: one, move to a different supported provider and transfer all of my domains. Or, two: write a script that could run as a validation hook and thus automate the whole thing.
|
||||||
|
|
||||||
|
> Certbot allows for the specification of pre and post validation hooks when run in manual mode. The flags to specify these scripts are --manual-auth-hook and --manual-cleanup-hook respectively and can be used as follows [...]
|
||||||
|
> This will run the authenticator.sh script, attempt the validation, and then run the cleanup.sh script. Additionally certbot will pass relevant environment variables to these scripts [...]
|
||||||
|
>
|
||||||
|
> -- https://certbot.eff.org/docs/using.html#pre-and-post-validation-hooks
|
||||||
|
|
||||||
|
Namecheap also [provides an API](https://www.namecheap.com/support/api/intro/) to anyone who has spent at least $50 within the last 2 years, [among other alternative requirements](https://www.namecheap.com/support/knowledgebase/article.aspx/9739/63/api--faq/#c).
|
||||||
|
|
||||||
|
## The solution
|
||||||
|
|
||||||
|
I wrote the manual auth hook found here: https://github.com/trwnh/namecheap
|
||||||
|
|
||||||
|
The hook I wrote uses Python, Requests, and BeautifulSoup. Since I just wanted the hook to work, I didn't bother over-engineering this -- this script has some limitations:
|
||||||
|
|
||||||
|
- Namecheap's API uses SLD and TLD instead of a singular domain variable. My script uses an extremely naive approach and simply splits the domain at the dot. I think this might not matter, but I haven't tested further because I don't own any domains with multipart TLDs.
|
||||||
|
- None of the API calls are paginated. This means the script only works on accounts with up to 20 domains. I own less than 20 domains, so this is not an issue for me. Also, the methods that require pagination are currently unused in the main function.
|
||||||
|
- No error checking or handling was implemented. Theoretically, the script could fail if the domain is expired or locked, but I trust myself to keep all my domains valid and registered.
|
||||||
|
- API username, key, etc. are hardcoded instead of being read from some external file. This script was written for my personal use, so I didn't bother going further.
|
||||||
|
|
||||||
|
### Logic
|
||||||
|
|
||||||
|
The pseudocode for this script is as follows:
|
||||||
|
|
||||||
|
1. Get CERTBOT_DOMAIN from Certbot.
|
||||||
|
2. Get the host records for this domain.
|
||||||
|
3. Get the CERTBOT_VALIDATION code.
|
||||||
|
4. Create a TXT host record using this challenge code.
|
||||||
|
5. Add this host record to the existing host records.
|
||||||
|
6. Upload the host records back to Namecheap.
|
||||||
|
|
||||||
|
The source code can be examined at https://github.com/trwnh/namecheap/blob/master/auth -- I made sure to leave docstrings and use clear function names, so hopefully this is good, readable code.
|
||||||
|
|
||||||
|
## The result
|
||||||
|
|
||||||
|
It works! Now, I can automate my certificate renewals instead of doing it all manually every three months. Maybe one day, I'll even write a cleanup script to delete the TXT challenge records... :)
|
||||||
23
content/code/liberapay-pleroma/index.md
Normal file
23
content/code/liberapay-pleroma/index.md
Normal file
|
|
@ -0,0 +1,23 @@
|
||||||
|
---
|
||||||
|
title: "Add Pleroma support to Liberapay"
|
||||||
|
summary: "Pleroma is compatible with the Mastodon API, but uses a different URL format. This pull request creates a Pleroma identity provider within Liberapay that takes this difference into account."
|
||||||
|
date: "2019-11-13"
|
||||||
|
tags: ["mastodon", "api", "pleroma", "liberapay", "contribution", "pull request", "github"]
|
||||||
|
cover: "/images/liberapay-pleroma.jpg"
|
||||||
|
---
|
||||||
|
|
||||||
|
pleroma is compatible with mastodon api.
|
||||||
|
only difference is url format:
|
||||||
|
|
||||||
|
- mastodon uses /@username
|
||||||
|
- pleroma uses /username
|
||||||
|
|
||||||
|
implementation notes: i've made it a separate provider than mastodon even though it implements the mastodon api for the following reasons:
|
||||||
|
|
||||||
|
- while there is no technical difference between auth flows or relevant apis, this may not be true in the future (although there are no plans afaik to change it in pleroma)
|
||||||
|
- renaming "mastodon" to "fediverse" is incorrect because not all fediverse servers implement the mastodon api
|
||||||
|
- labeling a pleroma as a "mastodon" account is technically incorrect
|
||||||
|
- given the above points, it was easier to just copy and paste and not deal with the potential for service explosion at this time
|
||||||
|
|
||||||
|
|
||||||
|
https://github.com/liberapay/liberapay.com/pull/1618
|
||||||
13
content/code/mastomods/index.md
Normal file
13
content/code/mastomods/index.md
Normal file
|
|
@ -0,0 +1,13 @@
|
||||||
|
---
|
||||||
|
title: "MastoMods"
|
||||||
|
summary: "CSS tweaks and modifications for Mastodon, a libre micro-blogging social server similar to Twitter."
|
||||||
|
date: "2019-02-18"
|
||||||
|
tags: ["mastomods", "mastodon", "css", "userstyles", "tweaks"]
|
||||||
|
cover: "/images/mastomods.jpg"
|
||||||
|
---
|
||||||
|
|
||||||
|
This work is heavily based on (and an extension of) my earlier work on Mastodon Flat CSS, and its child theme Linernotes Mastodon Themes. I grew tired of having to maintain what was essentially the same code in multiple different places, so this repo was created to be a more modular way of managing code snippets after I learned enough about how importing works.
|
||||||
|
|
||||||
|
linernotes_dark is an admin-installable theme that was commissioned for linernotes.club. Because the base MFC theme is adaptable, it is not too difficult to build your own theme on top of it. See the source code for comments and documentation.
|
||||||
|
|
||||||
|
https://github.com/trwnh/mastomods
|
||||||
11
content/code/obs-edit-transform/index.md
Normal file
11
content/code/obs-edit-transform/index.md
Normal file
|
|
@ -0,0 +1,11 @@
|
||||||
|
---
|
||||||
|
title: "OBS Studio: Ctrl+E to Edit Transform"
|
||||||
|
summary: "I added a shortcut to edit transforms on a source in OBS Studio."
|
||||||
|
date: "2017-04-30"
|
||||||
|
tags: ["obs", "open broadcaster software", "obs studio", "keyboard shortcut", "edit transform", "pull request", "github"]
|
||||||
|
cover: "/images/obs-transform.jpg"
|
||||||
|
---
|
||||||
|
|
||||||
|
Editing was very easy in OBS Classic, and I could not find the option for stretching a source to bounds in OBS Studio, so the "Edit Transform" dialogue should be more user-facing. Giving it a keyboard shortcut denotes that it is important enough to have a shortcut, as opposed to the myriad options with no shortcut.
|
||||||
|
|
||||||
|
https://github.com/obsproject/obs-studio/pull/894
|
||||||
26
content/code/photobucketgrabber/index.md
Normal file
26
content/code/photobucketgrabber/index.md
Normal file
|
|
@ -0,0 +1,26 @@
|
||||||
|
---
|
||||||
|
title: "PhotoBucketGrabber"
|
||||||
|
summary: "Download all your photos from PhotoBucket using this Python script."
|
||||||
|
date: "2019-03-17"
|
||||||
|
tags: ["python", "photobucket", "automation", "scripting", "archive", "export", "download"]
|
||||||
|
cover: "/images/photobucketgrabber.jpg"
|
||||||
|
---
|
||||||
|
|
||||||
|
## The problem
|
||||||
|
|
||||||
|
I had an old PhotoBucket account that I wanted to archive and delete. However, it would take an extremely long time to manually save each photo and recreate any albums' folder structure.
|
||||||
|
|
||||||
|
## The research
|
||||||
|
|
||||||
|
PhotoBucket allows copying direct image links, and it also allows copying multiple links at the same time. This is used to obtain a list of all photo direct URLs, which can be saved in a text file and read by a script.
|
||||||
|
|
||||||
|
Additionally, direct URLs maintain the folder and file names, so the path structure can be saved directly using Python's Path library.
|
||||||
|
|
||||||
|
## The solution
|
||||||
|
|
||||||
|
See my source code here: https://github.com/trwnh/PhotoBucketGrabber
|
||||||
|
|
||||||
|
Limitations:
|
||||||
|
|
||||||
|
- The prefix to be stripped is hardcoded, because it will always be the same for an account.
|
||||||
|
- There is no way to programmatically obtain a list of all photos or albums from Photobucket, as far as I know, so the selection step is still manual. I think for a one-time task, this is probably not an issue, as it would take more time to attempt to code a solution than it would to simply select all photos from the web dashboard.
|
||||||
28
content/code/salatime/index.md
Normal file
28
content/code/salatime/index.md
Normal file
|
|
@ -0,0 +1,28 @@
|
||||||
|
---
|
||||||
|
title: "salatime"
|
||||||
|
summary: "Basic terminal script to print out daily prayer times for Birmingham, AL."
|
||||||
|
date: "2019-05-09"
|
||||||
|
tags: ["python", "web scraping", "scraping", "beautifulsoup", "salat", "prayer", "time"]
|
||||||
|
cover: "/images/salatime.jpg"
|
||||||
|
---
|
||||||
|
|
||||||
|
## The problem
|
||||||
|
|
||||||
|
While working in a terminal environment, I would like to know what the current active prayer is, how much time I have left to pray, time to next prayer, and other such information.
|
||||||
|
|
||||||
|
## The research
|
||||||
|
|
||||||
|
The Birmingham Islamic Society provides tables of prayer times by month. This table can be scraped with Python Requests, then parsed with BeautifulSoup.
|
||||||
|
|
||||||
|
## The solution
|
||||||
|
|
||||||
|
Source code is available at https://github.com/trwnh/salatime
|
||||||
|
|
||||||
|
Pseudocode is as follows:
|
||||||
|
|
||||||
|
1. Get the current month, day, hour, and minute.
|
||||||
|
2. Get the page for the current month.
|
||||||
|
3. Get the times table out of this page.
|
||||||
|
4. Parse this table for a list of prayer times.
|
||||||
|
5. Parse this list for the current day's prayer times.
|
||||||
|
6. Calculate and print information.
|
||||||
|
|
@ -1,3 +1,3 @@
|
||||||
---
|
---
|
||||||
title: "Work I've done"
|
title: "Work done"
|
||||||
---
|
---
|
||||||
|
|
@ -110,9 +110,9 @@
|
||||||
</section>
|
</section>
|
||||||
<section class="section" id="contact">
|
<section class="section" id="contact">
|
||||||
<div class="container">
|
<div class="container">
|
||||||
<h2 class="section-heading" style="font-weight: 700">let's talk.</h2>
|
<h2 class="section-heading">let's talk.</h2>
|
||||||
<p style="max-width: 65ch; margin: 0 auto;">if you'd like me to do something for you, then the best way to get in touch with me is to email a@trwnh.com with your proposal. i am currently open for hiring as well.</p>
|
<p>if you'd like me to do something for you, then the best way to get in touch with me is to email a@trwnh.com with your proposal. i am currently open for hiring as well.</p>
|
||||||
<a href="https://resume.abdullahtarawneh.com" class="cta button" style="margin: 6em auto 0;">view resume</a>
|
<a href="https://resume.abdullahtarawneh.com" class="cta button">view resume</a>
|
||||||
</div>
|
</div>
|
||||||
</section>
|
</section>
|
||||||
</main>
|
</main>
|
||||||
|
|
|
||||||
File diff suppressed because one or more lines are too long
|
|
@ -1 +1 @@
|
||||||
{"Target":"scss/main.min.397e9f4be3c1c6acf6a7296d927f7de2c656cb95a7be3eca73cea90a66bab151.css","MediaType":"text/css","Data":{"Integrity":"sha256-OX6fS+PBxqz2pyltkn994sZWy5Wnvj7Kc86pCma6sVE="}}
|
{"Target":"scss/main.min.a33c5b7ac92a7c94b1f59dc550d96f946860187f3f8709040328040d6af77a50.css","MediaType":"text/css","Data":{"Integrity":"sha256-ozxbeskqfJSx9Z3FUNlvlGhgGH8/hwkEAygEDWr3elA="}}
|
||||||
BIN
static/images/liberapay-pleroma.jpg
Normal file
BIN
static/images/liberapay-pleroma.jpg
Normal file
{kind=link}
Binary file not shown.
|
After 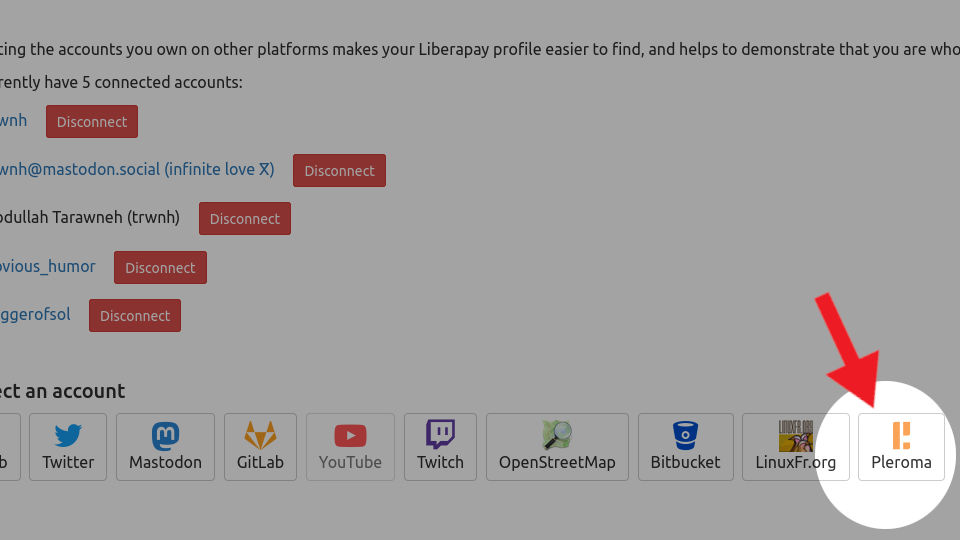
(image error) Size: 41 KiB |
BIN
static/images/mastomods.jpg
Normal file
BIN
static/images/mastomods.jpg
Normal file
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 54 KiB |
BIN
static/images/obs-transform.jpg
Normal file
BIN
static/images/obs-transform.jpg
Normal file
{kind=link}
Binary file not shown.
|
After (image error) Size: 51 KiB |
BIN
static/images/photobucketgrabber.jpg
Normal file
BIN
static/images/photobucketgrabber.jpg
Normal file
{kind=link}
Binary file not shown.
|
After 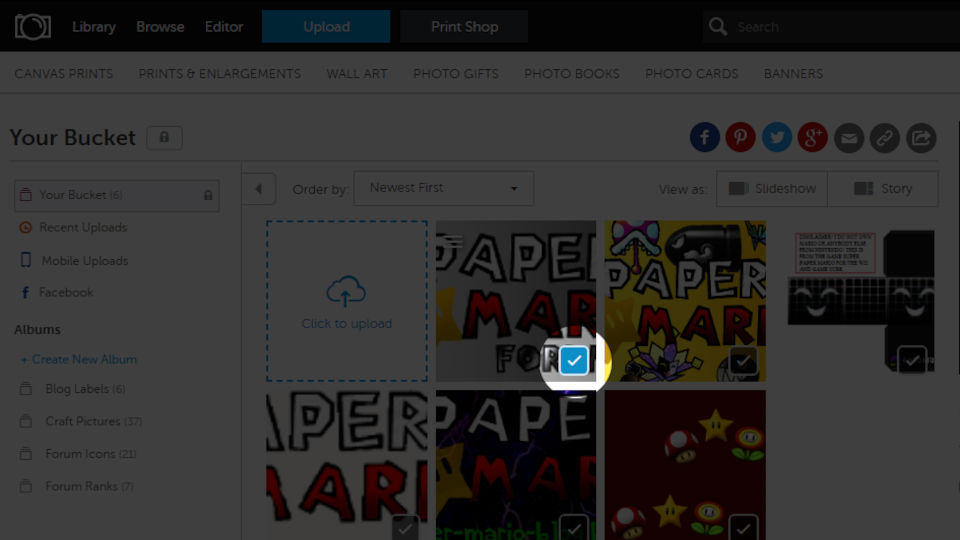
(image error) Size: 48 KiB |
BIN
static/images/salatime.jpg
Normal file
BIN
static/images/salatime.jpg
Normal file
{kind=link}
Binary file not shown.
|
After 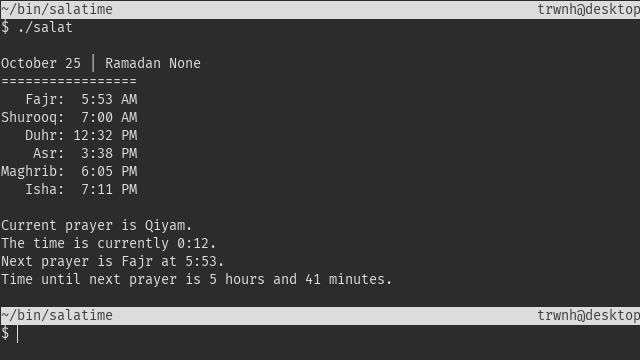
(image error) Size: 21 KiB |
Loading…
Add table
Reference in a new issue